- 当年 eBay 发起 Kylin 项目时,寄希望它能够将部分负载从昂贵的专有商业数据仓库如 Teradata 迁移到廉价、开放的大数据平台上。五年过去了,Kylin 凭借高性能和高可用性在 eBay 内部被广泛使用,而 Teradata 逐步被替换。今天,Kylin 在 eBay 每天服务数百万次查询,且大多数查询在 1 秒钟内完成。
- 美团、携程、京东、滴滴、小米、华为、丁香园,OLX 集团、汽车之家、Xactly 等许多公司都使用 Kylin 打造了他们的 DaaS(数据即服务)平台,为成千上万的分析师和租户提供数据服务。
- 一些微软 SSAS 的用户也正在逐步迁移到 Kylin 上,以承载更大的数据容量和获得更好的体验。
- 中国银联和某头部保险集团从 IBM Cognos 架构升级到 Hadoop + Kylin。因为分布式架构的优势,Kylin 对传统方案具备降维打击的能力,在某些场景中,一个 Kylin Cube 取代了数百个 Cognos Cube,不但管理运维的复杂度大大降低,并且具有更好的构建性能和查询性能。
- 建设银行、农业银行等已经使用 Kylin + Hadoop 来构建下一代大数据分析平台,解决扩容难和并发低的难题。
- 在 Kylin 中,你可以为每个分析主题或场景,创建一个或多个OLAP Cube;每个 Cube 都是面向特定主题的。
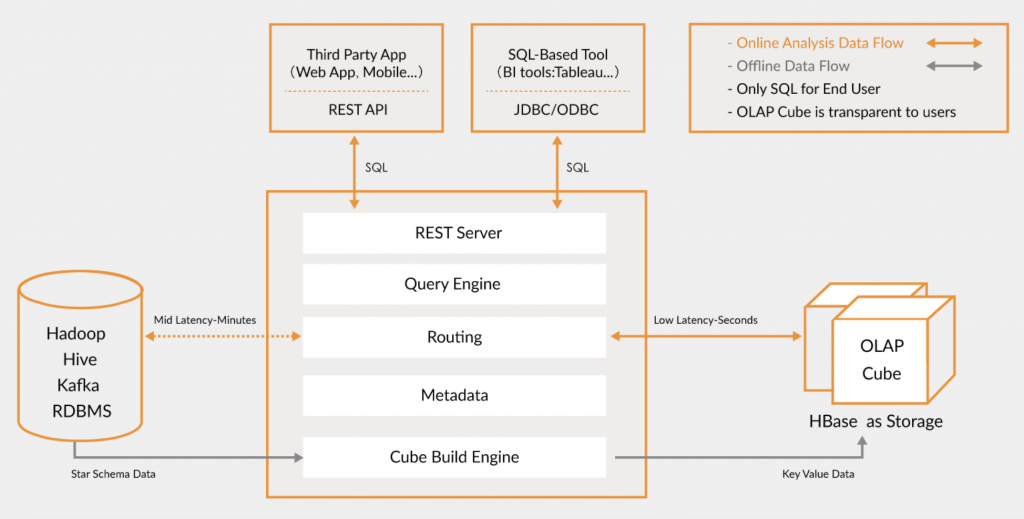
- Kylin 与 Hadoop、 Hive、Spark、Kafka 等系统实现了无缝集成,你可以在大数据平台上很容易地使用它。这也是为什么 Kylin 很容易被接纳的原因之一。
- Kylin会按照时间来分区加载数据,构建 Cube,然后保存为片段(也称分区);对于维度表,Kylin 每次会生成快照。这些数据在分析过程中是稳定的,不会随意改变。
- 当你在分析(上滚、下钻等)过程中,Kylin 的数据是稳定一致的,所有层级的汇总结果都严格一致。
- Kylin 提供了 SQL 查询接口和 JDBC/ODBC/HTTP API,用户将其与 BI/可视化工具(如 Tableau 等)轻松连接。